by Kevin Indig for kevin-indig.com
84% of sites are likely to block ChatGPT.
790 of the top 1,000 sites have a business model that’s not incentivized to give generative AI their data.
🗺️Context: An analysis of the top 1,000 sites on the web from Originality AI shows 12% already block Chat GPT’s crawler. (source)
- The number jumped from 9.3% on August 22nd to 12% on August 29th.
- Since then, I found more sites, like Amazon, blocking Chat GPT in their robots.txt.
- It’s unclear how Originality AI put the list of top 1,000 sites together, but the biggest ones are on it.
❗️But: Based on my analysis, the share of top 1,000 sites blocking Chat GPT is likely to jump up to 84%.
- How I got there: I grouped sites by business model and extrapolated who else is likely to block Chat GPT based on business models that are already blocking it.
- FYI: After deduping entries, I came to a total of 938 sites on the list. 60 are hard duplicates. Some sites are semi-duplicates = ccTLDs like google.com, google.ca, google.in, etc. that follow the same robots.txt guidance in every country.
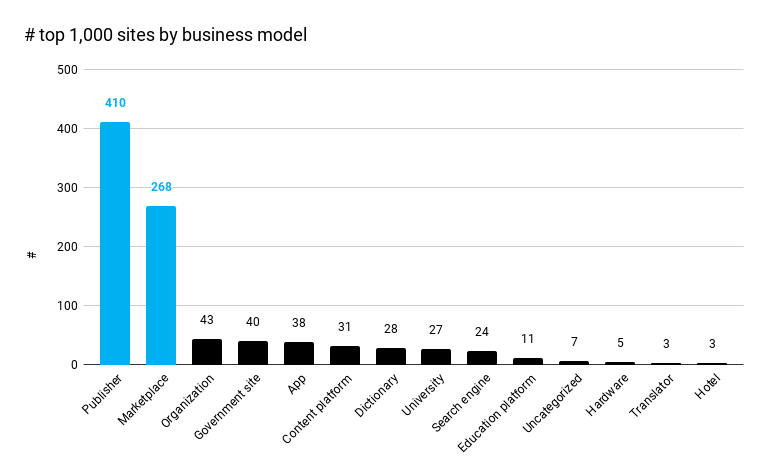
The business models and number of sites on the top 1,000 list (❌ = likely to block ChatGPT):
- ❌Publisher (410)
- ❌Marketplace (268)
- Organization (43)
- Government site (40)
- App (38)
- ❌Content platform (31)
- ❌Dictionary (28)
- University (27)
- Search engine (24)
- ❌Education platform (11)
- Uncategorized (7)
- Hardware (5)
- ❌Translator (3)
- Hotel (3)

A quarter (101/410) of publishers already block ChatGPT, followed by almost 15% of marketplaces (39/268).
Digging Deeper: What’s the value of appearing in Chat GPT?
Most sites lose more from sharing their data with Chat GPT than they gain. It can’t be used as a traffic channel, only for brand awareness.
For publishers, content is the product. Giving it away for free to generative AI means foregoing most if not all, ad revenue. Publishers remember the revenue drops caused by social media and modern search engines in the late 2,000s.
Marketplaces build their own AI assistants and don’t want competition.
- See: G2’s Monty, Tripadvisor’s AI planner, Course Hero’s homework helper or Quora’s AI assistant.
Chat GPT crawls the web for two reasons:
1/ Collect fresh data for answers because Chat GPT’s database only provides data up to September 2021.
- People use AI Chatbots like search engines because longtail searches on Google & Co still don’t yield good results.
2/ Improve models by training them on more data.
- Getting good data is difficult for AI model builders because they need signal that content is of high quality.
- That signal can come by valuing sources like the New York Times (professionals) or Wikipedia (moderation) higher than UGC, like Quora responses.
- Google and Bing have the advantage of using their ranking signals to prioritize high-quality content for model training.
Chat GPT’s crawler is not the only one that needs to be blocked if a site wants to prevent LLMs from crawling its content. It also has to block Common Crawl bot, Anthropic AI, and others.
- Will sites have to block Bing as well? Microsoft is likely to share crawl data with OpenAI due to their close partnership and since Chat GPT was already integrated with Bing until they pulled the plug.
🔄Asked the other way around: who wants their content to be indexed in chat GPT?
Answer: companies that don’t sell content but might use it to attract new clients
- SaaS companies
- Non-profits
- Universities
- Writers who want their ideas to spread
- Hardware sellers
- Apps
What this means for you: Should you block Chat GPT’s crawler?
Base your decision to block Chat GPT or not on your business model. If you’re a publisher, marketplace, content platform, dictionary, education platform or translator site, you probably want to block them.
- As a publisher, develop AI tools to make content creation more effective.
- As a marketplace, train AI models on your data and create your own assistant.
How I handle it: I’m letting LLMs crawl my site and include my ideas because I want them to be out there. If I were to ever launch a paid version of the Growth Memo, though, I’d block LLMs from crawling it.
🤖What this means for LLMs: More sites blocking GPTbot reflects the fear of being disrupted by AI. At the same time, LLMs need to find ways to ingest high-quality data.
- LLMs missed the opportunity to make it attractive for brands to be included in AI answers.
🚦One potential solution: OpenAI pays publishers for exclusive licenses to use content to train their models and enrich answers.
- In the US, digital ad revenue for publishers comes down to only $10b annually. If OpenAI really already makes a billion USD in revenue, it could pay selected publishers a licensing fee to compensate for ad revenue. (source)
- Open AI started a collaboration with The Associated Press, a non-profit, to trade data for product (source).